{kind=link}
{kind=link}
Vaclis Tone Replication (arXiv paper):
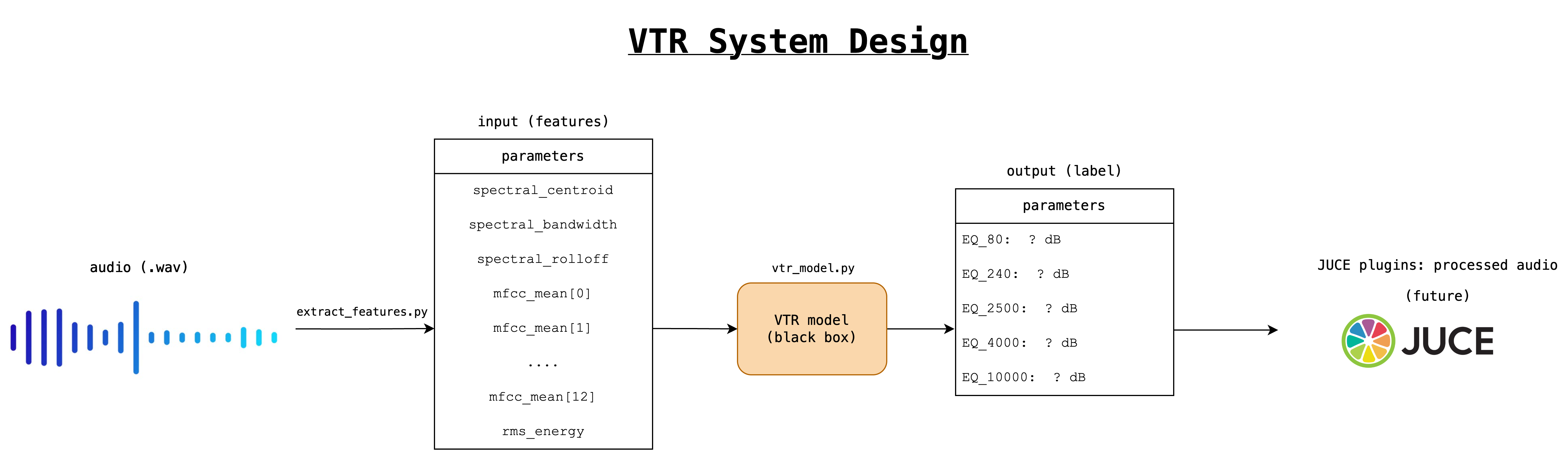
- An AI-powered system for tone replication in music production by predicting EQ settings directly from audio features.
- Creating a dataset of piano recordings with varied EQ parameters, our VTR neural network model accurately estimates multi-band EQ values (MSE: 0.0216).
- This approach provides musicians with practical, flexible, and automated tone matching, paving the way for future support of more complex audio effects.
- Feel free to scroll down the README or read the report file, poster or 5-minute-presentation.
As my experience, the Reascript in Lua causes some memory leaks problem, so it is not recommend to generate ten thousands of datasets all by once. (I used MacBook Pro M4 pro with 24GB mem, still totally run out of memory and crush...)
Hence, I write a script to seperate the for loop into subproblems by gen_data_batch_seperate.py.
Just simply run it and it will generate files like batch_01.lua.
In my case, to create 5 bands and {-12, -8, -4, 0, +4, +8, +12} dB gains, it has 7^5 = 16,087 files, and it should create 17 batch files.
- Open Reaper app → Actions > Show Action List
- In the filter section, search:
ReaScript→ click `ReaScript: Run/edit Reascript (EEL2 or lua) - Open the file ./autoEQ.lua and replace the
YOUR_VTR_DIRinto where you place the project andbatch_XXinto the batch you want to run.
If you want to test how many files you have done later on, you can comment some lines below in
gen_data_batch_seperate.py! It will list finished and unfinished files amount out.
Just simply run extract_features.py and you will get two files:
audio_features.csv: Audio features extract from audio files by python packagelibrosa. The features we collect are mentioned below, and the reason why I chose feel free to read my report and also feel free to add any features you want.
spectral_centroid,spectral_bandwidth,spectral_rolloff,mfcc_1,mfcc_2,mfcc_3,mfcc_4,mfcc_5,mfcc_6,mfcc_7,mfcc_8,mfcc_9,mfcc_10,mfcc_11,mfcc_12,mfcc_13,rms_energy
dataset_labels.csv: Ground truth for supervised learning model. I chose the below five frequencies, based on The Mixing Engineer's Handbook (2nd ed.), and also feel free to adjust to your case.
EQ_80,EQ_240,EQ_2500,EQ_4000,EQ_10000
Just simply run vtr_model.ipynb, and there includes full code of my baseline model (regression, random forest regressor) and main model (FFNN model).
